
Na fase inicial do desenvolvimento de um projeto de software realizam-se etapas importantes, como a análise de requisitos, levantamento dos atributos e relacionamentos presentes no sistema. Outra atividade indispensável nessa fase do projeto é reunir todos os dados e analisar a estrutura, a quantidade, os tipos e as relações desses dados. Com base nessa análise, é necessário decidir qual banco de dados é mais adequado e otimizado para armazenar e recuperar os dados desse sistema.
Tendo em vista as diferentes necessidades de cada aplicação, como por exemplo a escalonabilidade do sistema ou a agilidade da busca em um banco de dados muito extenso, surgiram novos bancos de dados que implementam diferentes paradigmas. Vale ressaltar que, atualmente, o paradigma relacional é um dos paradigmas de banco de dados mais utilizados em diferentes sistemas. No entanto, com o crescimento do volume de dados sendo gerados e com as diferentes possibilidades de estrutura desses dados, é possível notar que os bancos de dados relacionais podem apresentar algumas limitações em determinadas aplicações.
Neste artigo, apresentaremos um breve resumo sobre o funcionamento de sete paradigmas de bancos de dados: key-value (chave-valor); wide column; document oriented (orientado a objeto); relational (relacional); graph (grafo); search engine (motor de busca); e multi-model (multi-modelos).
Sete paradigmas de Bancos de Dados:
Paradigma Key-Value
O paradigma Key-Value (chave-valor) é o mais simples de todos os paradigmas de banco de dados. E conforme o nome já descreve, o banco de dados é estruturado como um objeto json que possui um conjunto de pares chave-valor, no qual cada chave é única e aponta para um valor. Pode-se armazená-lo como um inteiro, uma string, JSON (JavaScript Object Notation), um array, entre outros. Alguns dos bancos de dados mais populares que implementam este paradigma são Redis, Memcached Etc.

Os bancos de dados Key-Value usam estruturas de índice compactas e eficientes para localizar um valor de forma rápida e confiável por sua chave. Assim, tornam-se ideais para sistemas que precisam encontrar e recuperar dados rapidamente. Além disso, são fáceis de projetar e implementar.
Nesse banco de dados, os dados ficam salvos na memória RAM e não na memória rígida (disco – DISK). Isso limita a quantidade de dados para armazenamento, mas, em contrapartida, torna o banco de dados muito mais rápido. Outra desvantagem desse paradigma é a limitação da modelagem de dados, já que impossibilita realizar consultas (queries). Os bancos de dados Key-Value não têm uma linguagem de consulta, mas fornecem uma maneira de adicionar e remover pares de chave-valor. Sendo assim, não se pode consultar ou pesquisar os valores. Pode-se consultar apenas a chave.
redis> SET cor “azul”
redis> GET cor
>> “azul”
Na maioria das vezes, utiliza-se este paradigma como um cache para reduzir latência de dados. Grandes empresas como Twitter, Github e Snapchat utilizam bancos de dados que implementam este paradigma.
Paradigmas de bancos de dados – Paradigma Wide Column
No paradigma Wide Column (ou Column-family), adiciona-se uma nova dimensão se comparada com o paradigma Key-Value. Nos bancos de dados Wide Column, uma chave aponta para um conjunto de colunas e valores, tornando assim possível agrupar dados que se relacionam. Apesar de se assemelharem aos bancos de dados relacionais, os bancos de dados Wide Column não apresentam um schema (tabela), logo são capazes de lidar com dados não estruturados. Em vez de tabelas, esse paradigma apresenta estruturas chamadas column families, que contêm linhas de dados, onde cada linha define seu próprio formato. Os bancos de dados mais populares que implementam este paradigma são Cassandra e Apache HBase.
A linguagem de consulta utilizada no Cassandra é a CQL. Ela é muito similar a SQL, no entanto apresenta mais limitações, como por exemplo: não realizar uniões (joins) entre tabelas, tendo em vista que não existem tabelas neste paradigma.
Algumas das vantagens deste paradigma são: a velocidade das queries; a facilidade de escalonar e replicar dados; e um modelo de dados flexível. Além disso, por ser descentralizado é possível escalonar horizontalmente.
Geralmente, utiliza-se o paradigma Wide Column em situações em que há uma frequência de escrita dos dados no banco, mas não realizam-se leituras e updates desses dados com tanta frequência. Uma ótima aplicação para este paradigma é escalonar uma grande quantidade de dados de séries temporais, como registros de dispositivos IOT ou sensores.


Paradigma Document Oriented
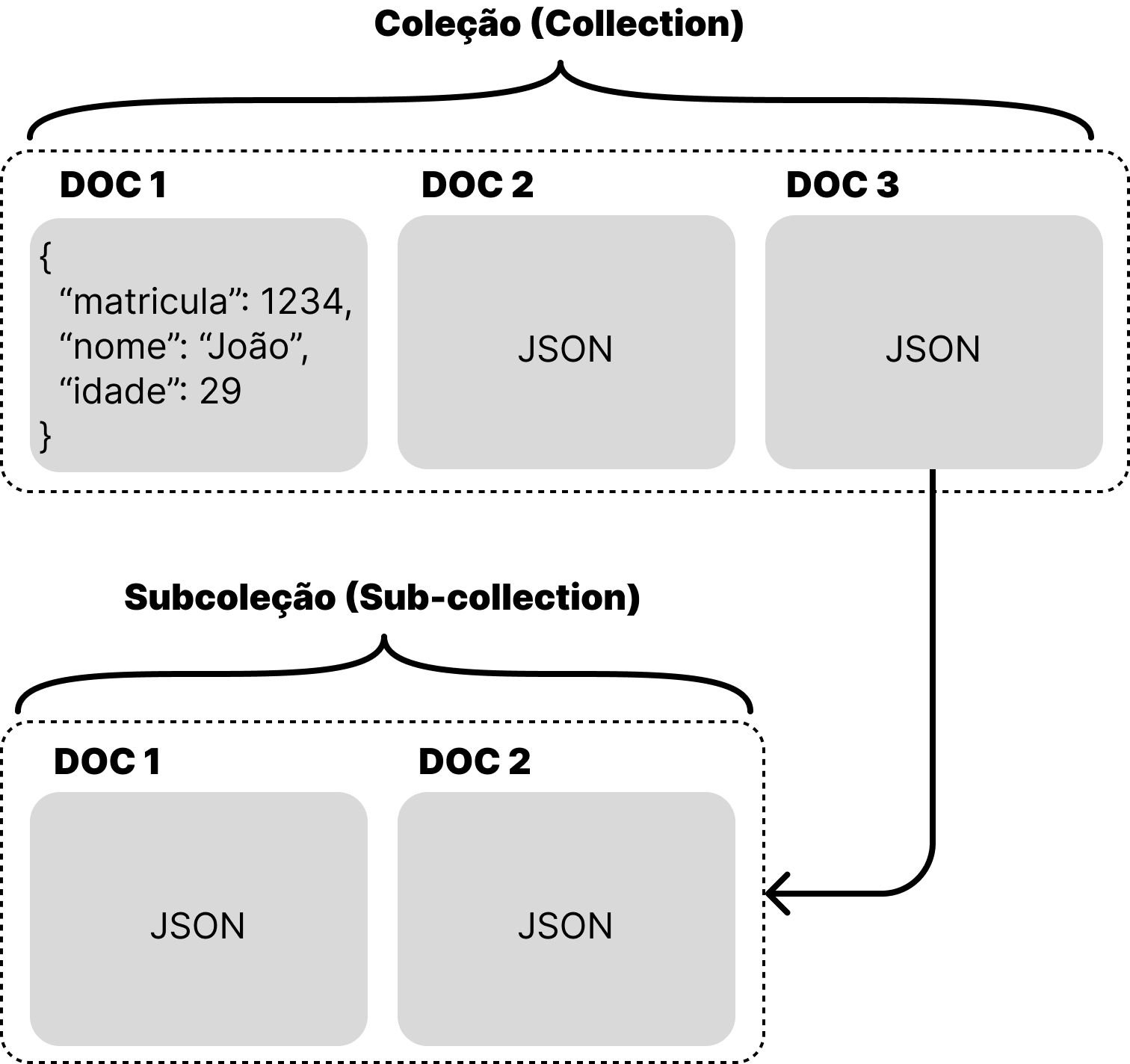
No paradigma orientado a documento (Document Oriented), armazenam-se pares de chave-valor dentro de documentos. E esses documentos são agrupados em coleções. Neste banco, os dados não são estruturados e não apresentam um esquema (schema). Este paradigma usa a semântica simples de chave-valor, mas também oferece a possibilidade de definir uma estrutura que facilite a consulta e operação dos dados no futuro. Os bancos de dados mais populares que implementam este paradigma são MongoDB, Firestore e CouchDB.
Os campos em uma coleção podem ser indexados e as coleções podem ser organizadas de forma hierárquica, permitindo a modelagem e recuperação de dados relacionais. No entanto, este paradigma não suporta joins, logo, ao invés de normalizar os dados recomenda-se agrupar esses dados em um único documento. Por consequência, ler o dado do banco se torna muito mais rápido, mas escrever ou atualizar os dados tende a ser mais complexo.
Uma das maiores vantagens dos bancos de dados orientados a objeto é a sua flexibilidade, tendo em vista que os documentos não precisam manter a estrutura idêntica. Sendo assim, é possível atualizar os documentos, adicionando novos campos, por exemplo, sem afetar adversamente outros documentos. Essa alta flexibilidade também implica em mais responsabilidade para manter a consistência e a estrutura dos dados, o que pode ser desafiador.
Já que cada documento dentro do banco de dados é independente, com seu próprio sistema de organização, este paradigma é uma boa opção quando não se sabe como se estruturaram os dados e/ou quando o desenvolvimento precisa ser rápido, pois é possível alterar as propriedades dos dados a qualquer momento sem alterar estruturas ou dados existentes. No entanto, este paradigma não seria uma boa escolha em casos onde os dados são relacionais e atualizados com frequência, como por exemplo um aplicativo de rede social.
Paradigmas de bancos de dados – Paradigma Relational
O paradigma relacional existe desde 1974. Ele foi criado pelo cientista de dados Ted Codd, e continua sendo o banco de dados mais utilizado em aplicações em diversas áreas. Os bancos de dados relacionais inspiraram a criação da linguagem SQL (Structured Query Language), que possibilita filtrar, agregar, resumir e limitar os dados retornados em uma query. Os mais populares deles, que implementam este paradigma, são MySQL, PostgreSQL, SQL Server e CockroachDB.
Ainda sobre os banco de dados relacionais, eles organizam seus dados em tabelas, estruturas que impõem um schema (esquema) aos registros contidos nelas. Estruturam-se as tabelas com linhas e colunas, onde cada coluna tem um nome e um tipo de dado. Além disso, cada linha representa um registro individual de dados na tabela, contendo valores para cada uma das colunas.
Modelo ACID
Os bancos de dados relacionais seguem o modelo ACID, quatro propriedades que preservam a integridade de uma transação:
- Atomicidade: uma transação é atômica (indivisível), ou seja, todas as ações que resultam na transação devem ser concluídas com sucesso para que a transação seja efetivada. Então, ou a transação será executada em sua totalidade ou não será executada e um rollback será realizado no banco de dados.
- Consistência: toda transação deve respeitar as regras/restrições de integridade dos dados descritas nos schemas do banco de dados.
- Isolamento: uma transação não sofrerá interferência de nenhuma outra transação concorrente, ou seja, em um sistema com múltiplos usuários, transações em paralelo não interferem umas nas outras.
- Durabilidade: as modificações realizadas por uma transação bem-sucedida são permanentes, podendo ser desfeitas somente por uma transação posterior e bem-sucedida. Sendo assim, os dados validados são registrados no banco de dados de tal forma que mesmo no caso de uma falha e/ou reinício do sistema, os dados estão disponíveis em seu estado correto.
Por obedecer as propriedades ACID, esse banco de dados é mais difícil de escalonar. No entanto, existem bancos de dados modernos, como o CockroachDB, que são especificamente construídos para operar com escalabilidade.
Geralmente, indicam-se os bancos de dados relacionais para dados regulares, previsíveis e que se beneficiem da capacidade de agregar informações de forma flexível. A estrutura altamente organizada conferida pela estrutura rígida das tabelas, combinada com a flexibilidade oferecida pelas relações entre as tabelas, torna esse paradigma muito poderoso e adaptável a muitos formatos de dados. A estrutura rígida das tabelas também reforça a integridade dos dados. Isso garante que os dados correspondam aos formatos esperados e que as informações necessárias sejam sempre incluídas.
Como esse paradigma organiza os dados de forma normalizada e requer schemas, se a estrutura dos dados não está bem estabelecida no início do projeto, torna-se ainda mais difícil implementar este banco de dados. Além disso, tornar-se mais desafiador alterar a estrutura dos dados no decorrer do desenvolvimento.

Paradigma Graph
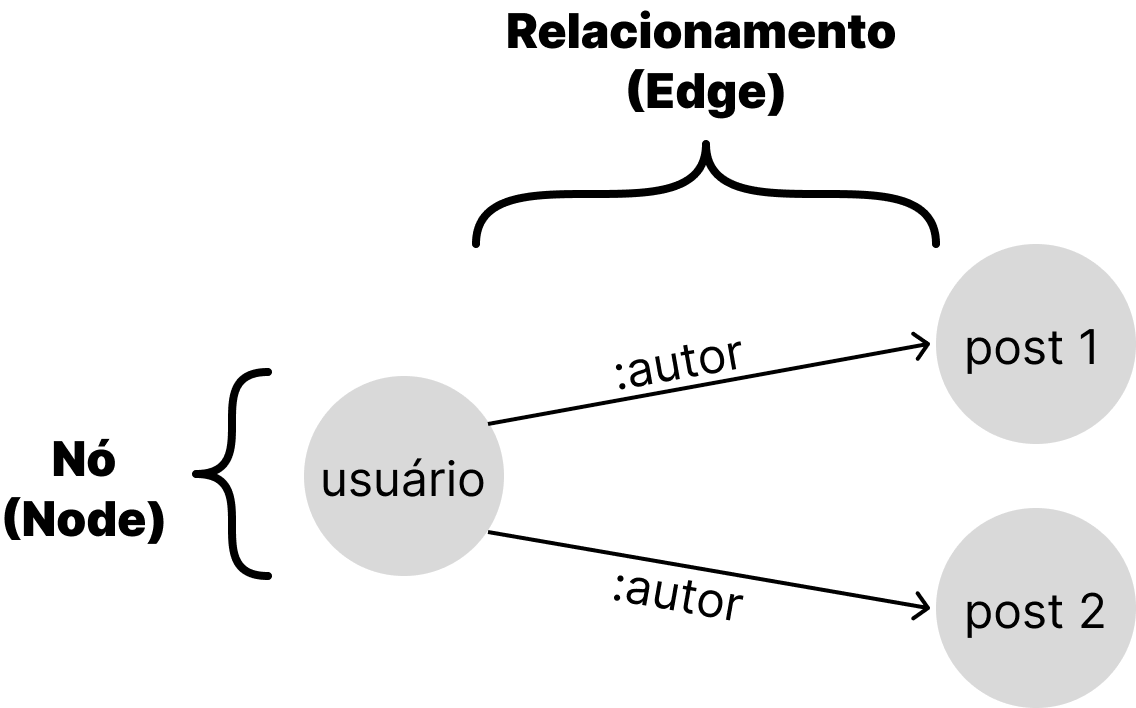
O paradigma orientado a grafos possui três componentes básicos: nós (vértices dos grafos); relacionamentos (arestas); e propriedades ou atributos. Ou seja, apresentam-se os dados como nós individuais, que podem ter qualquer número de propriedades associadas a eles, representando o relacionamento entre eles por arestas que conectam esses nós. Cada nó pode se conectar por mais de uma aresta. Os bancos de dados mais populares que implementam este paradigma são Neo4j, DGraph e Janus Graph.
Para realizar consultas em um banco de dados orientado a grafos, podemos usar um conceito chamado OGM (Object Graph Mapper), que pode ser implementado usando diversas linguagens de programação, como JavaScript, .NET, PHP e Java. Sendo assim, as queries são escritas com expressões mais concisas e legíveis.
A implementação deste paradigma é muito útil para lidar com dados em que os relacionamentos são muito importantes. Além disso, ele possibilita consultas mais complexas. Os bancos de dados orientados a grafos possuem alta performance, especialmente em datasets muito extensos.
Esse paradigma pode substituir o paradigma relacional, especialmente se, para obter as informações necessárias, realizarem-se muitos joins, afetando a performance da aplicação. Por exemplo, consultar a conexão entre dois usuários em um aplicativo de rede social utilizando um banco de dados relacional provavelmente exigirá várias junções (joins) de tabela e, portanto, consumirá muitos recursos. Realizar essa mesma consulta em um banco de dados orientado a grafos seria mais direto e eficiente, já que as conexões são mapeadas diretamente.
Paradigmas de banco de dados – Paradigma Search Engine
O paradigma motor de busca apresenta similaridades ao paradigma orientado a documentos. No entanto, a principal diferença é que internamente este paradigma vai analisar todo o texto de todos os documentos e criar um índice dos termos pesquisáveis. Assim, quando um usuário faz uma busca é necessário escanear apenas o índice ao invés de buscar em todos os documentos do banco de dados. Essa busca textual otimizada torna esse paradigma muito rápido mesmo em bancos de dados enormes. Os bancos de dados mais populares que implementam este paradigma são ElasticSearch, Algolia e MeiliSearch.
Uma grande vantagem da utilização desses bancos de dados é a possibilidade de utilizar diversos algoritmos para ranquear os resultados, filtrar dados irrelevantes, lidar com erros de digitação, entre outros. Este paradigma é ideal para motores de busca textual, facilitando muito o processo de recuperação de informações relevantes, permitindo que os usuários pesquisem informações com texto em linguagem natural.

Paradigma Multi-Model
O paradigma multi-modelo combina a funcionalidade de mais de um paradigma. Consequentemente, o mesmo banco de dados é capaz de usar diferentes representações e estruturas para diferentes tipos de dados. Os bancos de dados mais populares que implementam este paradigma são FaunaDB e CosmosDB.
Internamente o banco de dados analisa e decide como se beneficiar de múltiplos paradigmas de banco de dados, se baseando no código GraphQL que o usuário insere. Para recuperar as informações, apenas definimos o modo de consumo dos dados, e o banco de dados se encarrega de modelar e estruturar os dados.
Os bancos de dados multi-modelo também seguem os princípios ACID (Atomicidade, Consistência, Isolamento e Durabilidade) e são muito rápidos. Outra grande vantagem é a possibilidade de manipular os dados armazenados em diferentes paradigmas de banco de dados em uma única consulta. Além disso, esses bancos de dados também contribuem para manter a consistência dos dados, o que pode ser complexo ao realizar operações que modificam dados em vários tipos de bancos de dados ao mesmo tempo.
Utilizar um banco de dados multi-modelo garante mais flexibilidade no processo de desenvolvimento de um projeto, permitindo assim a alteração ou expansão das estruturas dos dados e dos paradigmas a partir das necessidades do projeto. Outro ponto positivo é não precisar aprender uma nova ferramenta de banco de dados, caso seja necessário mudar o paradigma que estrutura os dados.
Conclusão – Paradigmas de bancos de dados
Uma das decisões mais importantes ao iniciar um novo projeto é definir a estrutura organizacional que melhor atende às demandas desse projeto. Cada um dos paradigmas mencionados acima apresenta vantagens distintas que valem a pena serem exploradas. Portanto, aprender o que cada paradigma de banco de dados oferece pode ajudar a reconhecer quais sistemas viabilizam as melhores soluções para todos os diferentes tipos de dados e estruturas.
É fundamental ressaltar que nenhum paradigma é superior a outro. Na realidade, cada paradigma é mais adequado para ser utilizado em certas situações, e cabe aos desenvolvedores identificar qual dos paradigmas de banco de dados se encaixa melhor com a aplicação sendo desenvolvida. Inclusive, muitas vezes, implementar diferentes paradigmas de banco de dados é a melhor abordagem para lidar com os dados de seu projeto.
Quem é a Aquarela Analytics?
A Aquarela Analytics é vencedora do Prêmio CNI de Inovação e referência nacional na aplicação de Inteligência Artificial Corporativa na indústria e em grandes empresas. Por meio da plataforma Vorteris, da metodologia DCM e o Canvas Analítico (Download e-book gratuito), atende clientes importantes, como: Embraer (aeroespacial), Scania, Mercedes-Benz, Grupo Randon (automotivo), SolarBR Coca-Cola (varejo alimentício), Hospital das Clínicas (saúde), NTS-Brasil (óleo e gás), Auren, SPIC Brasil (energia), Telefônica Vivo (telecomunicações), dentre outros.
Acompanhe os novos conteúdos da Aquarela Analytics no Linkedin e assinando a nossa Newsletter mensal!
Autora

Graduada em Engenharia Elétrica pela Universidade Federal de Campina Grande (UFCG), com ênfase em Controle e Automação. Desenvolvedora Python na Aquarela Analytics, com foco na construção de APIs. Na área de Engenharia de Dados trabalha com modelagem de dados, e com a criação e estruturação de ETLs. Entusiasta na área de Machine Learning e Ciência de Dados.








1 Comment
Gostei muito do texto. Esclareceu as diferenças entre os paradigmas, e destacou muito bem a importância de escolher o tipo de banco de dados com base em cada projeto.